What is a Data Lake?
The term 'Data Lake' is a metaphor describing data storage that does not discriminate on what data types* are stored in it (*data types = structured, unstructured, semi-structured).
As data navigates through the data lake, it undergoes cleaning, integration, and potentially aggregation to make it usable and useful. All these activities require computing power that interfaces with the data lake, extracts and manipulates the data, and then reintegrates it into the data lake.

In this method, comprehension and interpretation of ingested data are done the moment the data is stored as opposed to Schema-on-Write, where the structure for the data is established beforehand, during the information's creation.
Best Approaches for Creating a Data Lake.
Of course, the biggest favour you can do for yourself as you create a Data Lake is to ensure it doesn't end up a Data Swamp.
Designing a data lake should not be considered a trivial task. It is a time-consuming process and before designing it, users must know what types of data are being used, at what volumes and how frequently are data being updated.
Divide the data lake into multiple layers (also called zones)
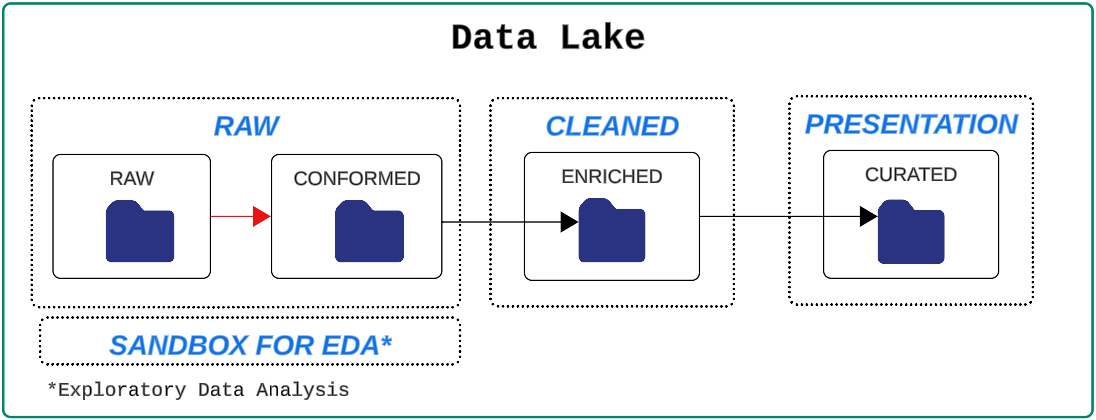
- Each layer has an increasing data quality index i.e. data quality improves as it moves from left to right (Raw to Cleaned).
- RAW:
- Raw
- Reservoir for data in its original state.
- Data is unfiltered and unpurified.
- This layer is also called the Bronze Layer or Landing Layer.
- Conformed
- Data is transformed into a common storage file format (Parquet is the most popular format but CSV and JSON can also be used).
- Also called the Base or Standardized Layer.
- Raw
- CLEANED:
- Enriched
- Data is available as consumable datasets.
- Also called Silver, Tranformed, Refined, Processed or Enriched.
- Enriched
- PRESENTATION
- Curated
- This layer is business-facing i.e. non-technical resources can connect to it to satisfy their reporting needs.
- Also called Trusted, Gold, Production, Curated, Analytics or Consumption.
- Curated
- RAW:
- SANDBOX
- Used by data scientists, analysts and others for exploration and playing with the raw data.
Divide the data lake into folders
This approach provides a lot more flexibility and, not surprisingly, an opportunity to shoot oneself in the foot, if not cautious. Folders can be considered 'zones' and their arrangement should be driven by decisions made collaboratively.
Examples of folder structures are:
- Save data into folders per business unit.

- Save data into folders broken down by specific roles.
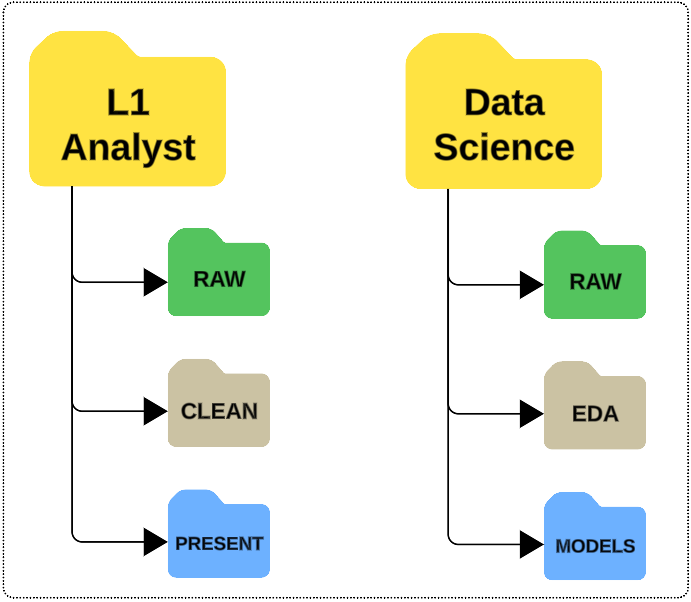
- Save data in a folder named after the data lifecycle stages.
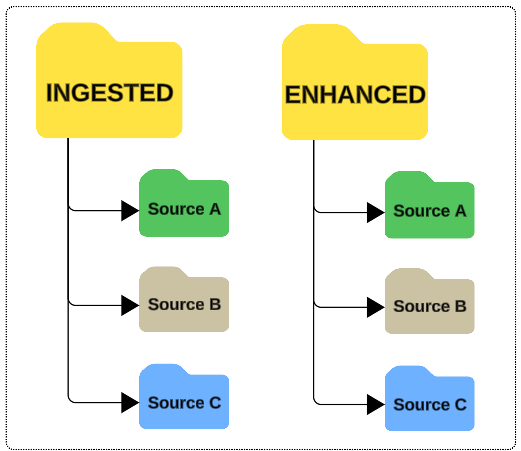
- Time partitions (the day data was ingested)
- Frequency data folder/zone is accessed (e.g. Hot, Cold, Lukewarm)
- Owner's name
- Sensitivity of data (e.g. open access, limited access, top secret)
I write to remember, and if, in the process, I can help someone learn about Containers, Orchestration (Docker Compose, Kubernetes), GitOps, DevSecOps, VR/AR, Architecture, and Data Management, that is just icing on the cake.