LLMOps: Here we go again?
Let's start from the top by answering the question: What are LLMs?
So, what are they?
They are statistical models, trained on massive amounts of text in the hope that we can emulate human speech using Natural Language Processing. Tasks such as text classification, speech synthesis and summarization are the building blocks of any LLM's outputs.
Ok, got it, and what is LLMOps then?
The principles of DevOps and Agile are the basis for a new framework, used exclusively to deploy LLM applications, which is called LLMOps.
LLM services are exposing their models as API's and this allows the average person to develop their own applications via integration with these LLM models. Some truly innovative apps have been developed using LLMs (Glean is an excellent example of one such app) and like any software-system, these innovative apps will keep beefing up their capabilities, and of course, as and when a change is made to the app, it has to be tested, deployed and then monitored, much like ANY other software we develop. This is where LLMOps enters the fray.
Once more unto the breach, dear software developer friends.
You used CICD pipelines, with artifact repositories and GitHub repos to continuously deploy new code. LLMOps does the same, but specifically for LLM based applications. We can state with great certainty, therefore, that LLMOps is a framework that provides a tactical framework for operationalizaing LLMs (and LLM based applications), as efficiently as is possible.
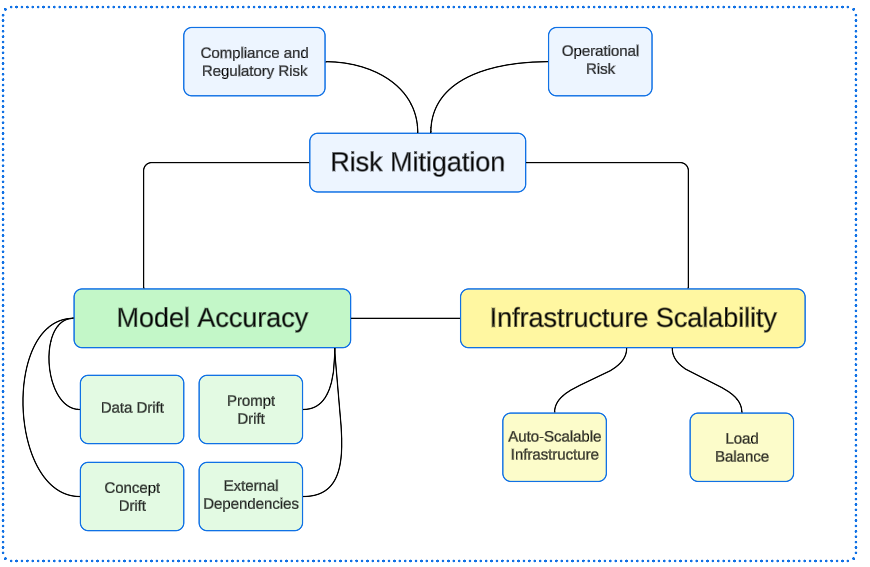
LLMOps teams, much like DevOps teams, want to integrate different development tasks (coding, testing and deploying, securing and data management) that may be spread across functional units. As LLMOps teams get mature, they should automated where they can, shift left where it makes sense and continually monitor* both the health of the model and the accuracy of its outputs.
- Defining SLOs
- Keeping infrastructure stable, available, and fault-tolerant
LLMOps must have 3 core goals, and anything additional is icing on the cake.
LLM models are incredibly difficult to debug. They are a breeding ground for most of the 'bad' things AI does, like provide biased results, generate an output that puts users in harms way or just be incorrect (and therefore, less valuable).
LLM Lifecycle and Automation
Before we automate a process, we have to be aware of it. The LLM Model Lifecycle process is shown below.
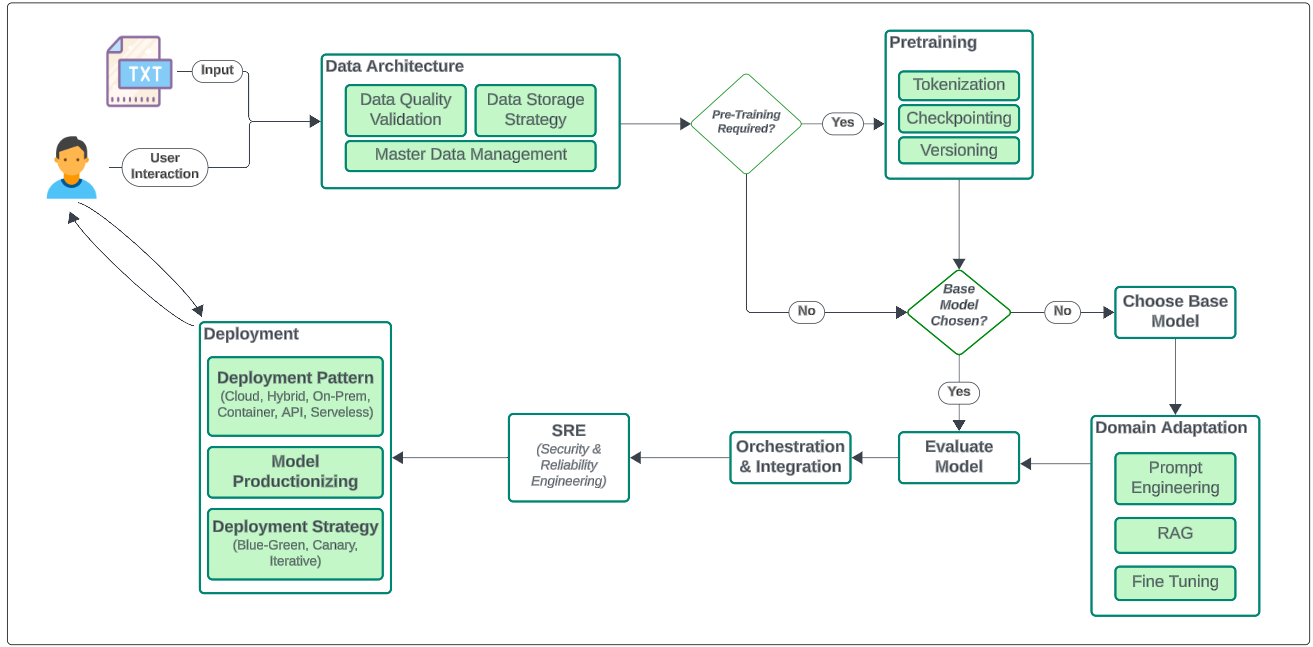
Data Architecture
Salient activities in this step are:
- Data Pipeline Configurations
- Data Ingestion
- Data Preprocessing (tokenize, augment, mitigate bias, sanitization)
- Data Storage
- Data Governance (cataloging, versioning, master data updates)
Pretraining
Pretraining includes
- Tokenization (breaking of text into smaller chunks)
- Checkpointing (saves intermediate states of model during training)
- Versioning (saves trained LLM models as they keep getting tuned)
Choosing a Base Model
Always ask, at least, the questions below, before deciding which LLM model suits your needs (and capacity) best:
- Is model transparent and interpretable?
- Is the model tested on a 'robust set of scenarios' to assess its own robustness?
- Is the training data used for the model readily accessible?
- Is the training dataset biased and therefore, limited in its ability to provide a fair and equitable outcome?
- Have the model makers understood the bias and already taken steps to counter it?
Domain Adaptation
In cases where you are using pre-trained general models for a specific domain (e.g. Healthcare), the model has to be adapted to the nuances of the domain.
Domain Adaptation is achieved using:
- Prompt Engineering
- Retrieval Augmented Generation
- Fine Tuning using techniques like Adapter-Based fine-tuning, Paratemer-Efficient Fine Tuning and Full fine-tuning.
Model Evaluation
The magic of Gen AI is its creativity. Depending upon inputs, model and training datasets, the outcomes of using a model with a defined set of inputs may not produce the same outputs everytime. It is therefore EXTREMELY challanging to test LLM models though its not impossible. There are monitoring and tracing tools that can be made part of the models lifecycle, and contain metrics-based evaluation functions that provide some insight into a models performance.
Orchestration & Integrations
Orchestration is like being the conductor of an orchestra, making sure every task hits the right note at the right time. It involves coordinating and optimizing workflows to automate and streamline activities like data collection, model training, and evaluation. Orchestration is key for ensuring tasks are executed in the correct sequence, helping LLM engineers scale, manage resources, and efficiently use infrastructure by parallelizing or distributing workloads.
Integration is like getting all your favorite gadgets, tools, systems, and code to play nicely together, creating one awesome, unified solution. In the world of LLMOps, this means bringing together the user interface, data sources, different base models, RAG pipelines, loggers, and deployment environments to ensure everything flows smoothly. Some of the top integration frameworks for LLMs are Langfuse, LangChain, LlamaIndex, and Griptape.
SRE (Security and Reliability Engineering)
LLMs have a MASSIVE surface area of exposure, considering millions of users interact with them everyday/hour/min. In addition, there are third party integrations, which may have vulnerabilities of their own.
LLMs require a very deep and stringent approach to security and privacy because the first instance of personal information being leaked at the scales of an Okta or Sony and becoming public will likely be a significant blow to LLM popularity.
Deployment
Deployments can be based on a Pattern supported by a strategy.
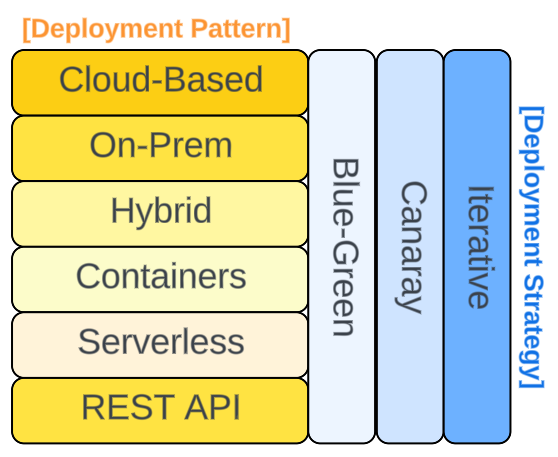
Some considerations before deciding the right Pattern are:
- Is access control necessary and if yes, how strong should it be?
- Is the LLM going to experience a lot of requests and is there a known busy time vs down time for the traffic?
- This information can be used to scale resources on the fly.
- How big is the LLM’s context window?
- Is the model's architecture and training parameters part of an intellectual property and therefore need to be kept private?
I write to remember, and if, in the process, I can help someone learn about Containers, Orchestration (Docker Compose, Kubernetes), GitOps, DevSecOps, VR/AR, Architecture, and Data Management, that is just icing on the cake.