K8s Scheduling: Schedule Pods Based on Resource Needs.

Being an Orchestration engine, it is incumbent upon K8s to ensure Pods are running at all times. Barring a mistake in a Deployment/Pod manifest (or other human induced errors) , there is no excuse for it/them to not be up and running.
In this regard, the kube-scheduler is a vital part of the K8s ecosystem. It is a Control Plane component and is always looking for Pods that should be running on a Node(s) but are not. When such Pods are found (such Pods don't have a Node name in their object), the scheduler jumps into action and makes it a mission to find a home for them.
Table of Contents
- A High Level View of the Scheduling Flow
- Demo: Scheduling 3 Pods on a 4 Node Cluster
- Demo: Scheduling 6 Pods on a 4 Node Cluster
- Demo: Scheduling Pods with Resource Requests
A High Level View of the Scheduling Flow
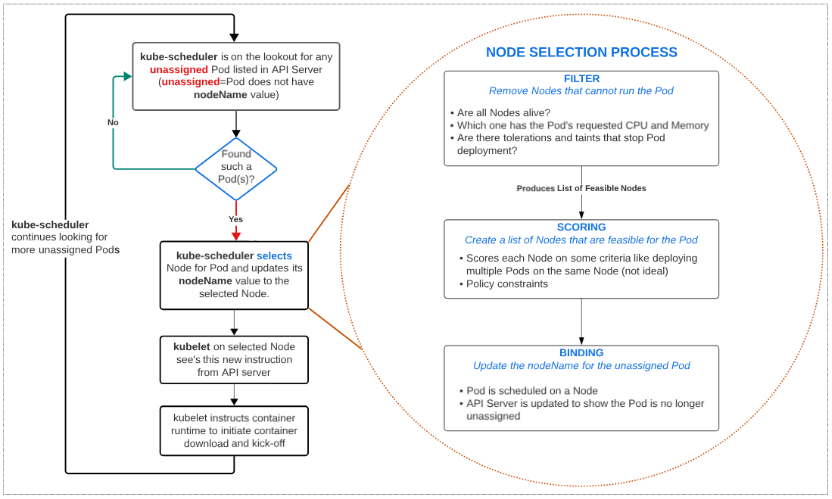
- kube-scheduler finds unassigned Pods (i.e. Pods that have no Node name in their object model).
- kube-scheduler selects the right Node for the unassigned Pod(s)
- kube-scheduler updates API server with the name of the Node that can handle the Pods needs
- kubelet, running on Nodes, see new Pod(s) have been assigned to its Node
- kubelet tells container runtime to download and start up the container images
For demos in this article, we will assume a cluster with 1 Control Plane Node and 3 Worker Nodes.
| Node Type | IP |
| Control Plane | 192.168.0.214 |
| Worker Node 1 | 192.168.0.96 |
| Worker Node 2 | 192.168.0.205 |
| Worker Node 3 | 192.168.0.186 |
Demo: Scheduling 3 Pods on a 4 Node Cluster
Step 1: Deploy the manifest with 3 replicas

kube-scheduler filtered out the Node which could NOT host the Pods (in this case, the Control Plane) and placed on Pod each on one of the 3 Worker Nodes.
Demo: Scheduling 6 Pods on a 4 Node Cluster
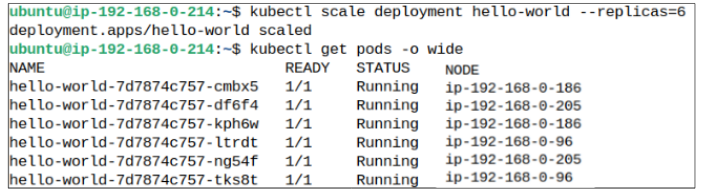
Following on from our previous example, if we were to scale up our replicas to 6, from the 3 it currently is, what would we observe about Pod deployments per Node?
Step 1: Scale up replicas to 6
Demo: Scheduling Pods with Resource Requests
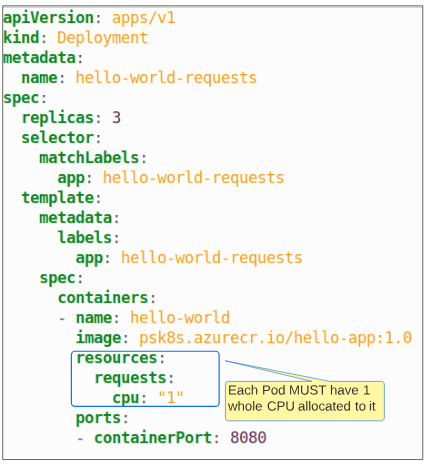
In this demo, we will add a resource request in our Pod spec and examine the outcomes as far as Pod deployment is concerned.
Step 1: Deploy the manifest provided for this demo
Step 2: Display Pods using $ kubectl get pods -o wide

Step 3: Increase replicas to 6
Increase replicase from 3 to 6 by typing $ kubectl scale deployment hello-world-requests --replicas=6.
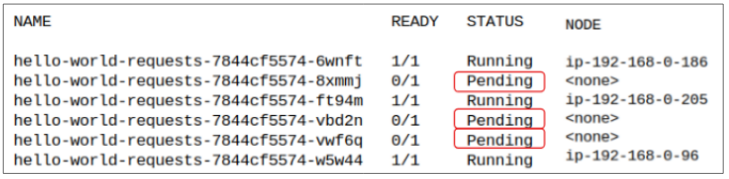
To answer the 'Why', lets look at Node ip-192-168-0-186 (or any of the other 2 for that matter - the deduction in all cases will be the same).
Observation # 1: The Node has 2 CPUs

Observation # 2: One of the CPU's has been allocated to 1 of the 2 Pods that were scheduled for this Node.

Observation # 3: The calico-node-hntd6 Pod has a request for 250 millicore of a CPU.

The remaining CPU capacity of 750 millicore is not sufficient for any other Pod (from this Deployment, at least) and therefore, after the first 3 are deployed, and kube-scheduler comes back to the remaining 3, there is not enough CPU for them.
This lack of resources puts the Pods in a PENDING state and till resources are increased OR Pod requests are lowered, they will stay in this state.
I write to remember and if in the process, I can help someone learn about Containers, Orchestration (Docker Compose, Kubernetes), GitOps, DevSecOps, VR/AR, Architecture, and Data Management, that is just icing on the cake.