K8s Scheduling: Affinity & Anti-Affinity for Pod Placement.

Webster defines affinity as
a spontaneous or natural liking or sympathy for someone or something.
The idea of Affinity/Anti-Affinity is an enhanced version of nodeSelectors/labels that can be used for scheduling Pods.
In this article, we will talk about Affinity and Anti-Affinity at the Node and the Pod level, though the outcomes of both is the same: ideal placement of the Pods that form the backbone of any running system.
Table of Contents
- Mechanisms to influence Pod deployment
- Node Affinity
- Demo: Pod Placement Using Node Affinity
- Pod Affinity
- Demo: Pod Placement Using Pod Affinity
- Pod Anti-Affinity
- Demo: Pod Placement Using Pod Anti-Affinity
Mechanisms to influence Pod deployment
K8s has at least 5 different ways of controlling where Pods get scheduled:
- Node Selectors
- Affinity and Anti-Affinity
- Taints and Tolerations
- Node Cordoning
- Manual Scheduling
Node Affinity
In terms of the core logic behind Node Affinity, its not much different than Node Selector labels. With Node Selectors, a Node/Nodes has/have a label and a Pod specifies in its specification that it wants to be placed on a Node with that label. The kube-scheduler will find such a Node and schedule the Pod on it. End of story.
However, with Node Affinity, in addition to simple equality based selections, we can use more complex checks and boolean logic, allowing kube-scheduler flexibility in where it places a Pod.
Two complex checks/boolean logic predicates, used in Affinity and Anti-Affinity scheme are
- requiredDuringSchedulingIgnoredDuringExecution and
- preferredDuringSchedulingIgnoredDuringExecution.
requiredDuringSchedulingIgnoredDuringExecution expects all its child conditions to be TRUE for a Pod to get placed on a Node (or some other Pod) while preferredDuringSchedulingIgnoredDuringExecution would really like for all the conditions to be met before scheduling a Pod but will not stop the placement if they are not.
IgnoredDuringExecution means that if the node labels change after Kubernetes schedules the Pod, the Pod continues to run.- Control Plane: 192.168.0.214
- Worker Node 1: 192.168.0.96 (has a label node=WN1)
- Worker Node 2: 192.168.0.205 (has a label node=WN2)
- Worker Node 3: 192.168.0.186 (has a label node=WN3)
Don't know how to label Nodes? Look here for tips.
Demo: Pod Placement Using Node Affinity
A quick visualization of what we are trying to achieve with this demo is shown in Figure 1 below:
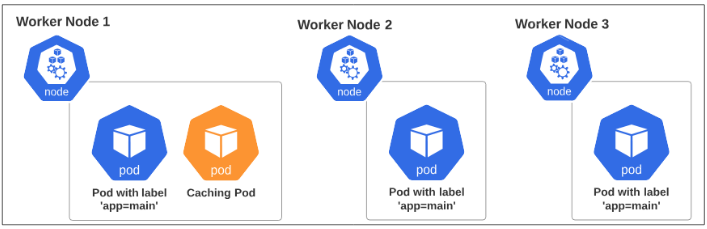
Our goal is:
- Deploy a Pod with label app=main on each of the 3 Nodes
- Deploy a Pod for caching on Worker Node 1 ONLY
Step 1: Deploy 3 Pods, which have a label app=main, on each of the Worker Nodes.

Step 2: Create the Deployment manifest for the Caching Pod.

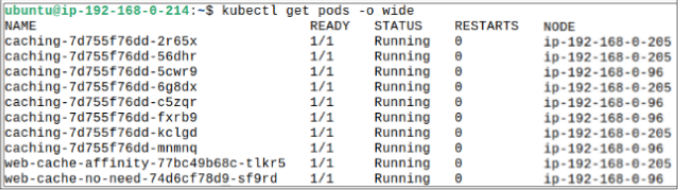
Step 3: Check where the Pod was placed.
After deploying this manifest, check where the Pod was placed using $ kubectl get pods -o wide.

What if we scaled the cache Pod to 3 replicas? Would they still be placed on the same Node or will they be distributed across all Worker Nodes?
This can be quickly confirmed by scaling the caching Deployment and checking Pods placement using kubectl get pods -o wide.
Step 4: Scale caching to 3 replicas using kubectl scale deployment caching --replicas=3.
Checking the Pods placement again, we see all 3 cache Pods were deployed on Worker Node 1.

Pod Affinity
Just like Node Affinity, Pod Affinity also uses a combination of labels and complex matching expressions to tell kube-schedule where it wants to be placed.
Demo: Pod Placement Using Pod Affinity
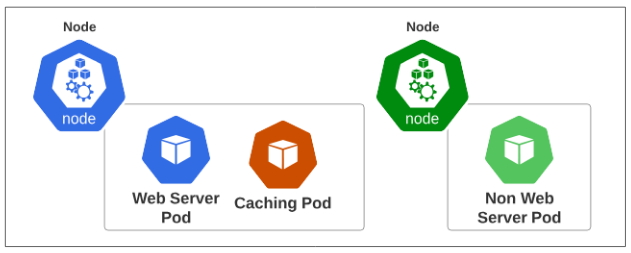
The architecture we are aiming for is attempting to do the following: for every Node in the cluster where there is a web server Pod, there MUST be a caching Pod.
Visually, we are striving for the following type of Pod placement policy:
Step 1: Deploy a simple web server Pod.

Step 2: Deploy another web server Pod but with a different label.
To show Affinity between caching and web server Pods, lets deploy another simple Pod but for this one, instead of using web-cache-affinity as a label, use web-cache-no-need.
Once deployment is complete, confirm 2 Pods (one with web-cache-affinity and the other with web-cache-no-need as labels) are running.

Step 3: Deploy the caching Pod.
The manifest for the caching Pod clearly states its preference to be paired with any Pod which has the label app=web-cache-affinity.

What's the deal with this attribute called topologyKey?
Every object in K8s (and in most cases, should) has labels applied to it, making it easier for Kube-API to find whatever its looking for. If you've been reading the previous articles in this series, you must have noticed that nearly all scheduling techniques shown so far (i.e. Node Selector, Node Affinity and now Pod Affinity) are utilizing some kind of string matching. The idea behind topologyKey is also (no drum rolls here, please) based on labels and string matching. However within the context of Pod Affinity/Anti-Affinity, this kind of label matching can also be referred to as topologyKey.
But what does it mean? Why do I have to use it in my manifest?
In Pod Affinity, we want a Pod A (in our demo, the caching Pod can be considered Pod A) to be deployed in some kind of close proximity to another Pod B (which is the web server Pod for us).
Close proximity can mean that Pod A and Pod B can be on the same Node or they can be on different Nodes but in the same Zone. Based on needs and requirements, we may be ok with Pod A and Pod B being placed on different Nodes in the same zone or same Node in the same zone. Now, if we left the placement of these Pods to kube-scheduler, it will follow its built-in-one-size-fits-all scheduling algorithm and we may not get the Pods placed as per our requirements.
It is therefore important for us to provide direction to the kube-scheduler, as part of our Pod specs, and ensure we get the sort of architecture we need. It is for this direction setting that the topologyKey is used.
toplogyKey values are set as labels (either applied during installation or by users) for every Node that becomes part of the cluster.
In Figure 9, the topologyKey value is set to kubernetes.io/hostname which tells kube-scheduler to 'deploy or co-locate the caching Pod on the same Node as the web server Pod'.
If the topologyKey was set to topology.kubernetes.io/zone, the caching Pod could have been placed on a Node other than the one on which the web server is deployed as long as they are both in the same availability zone (e.g us-west-1, ca-central-1, us-east-1 and so on).
Step 4: Check where the Pods (web server and caching) are placed.

If you were to scale up caching Pod to, say, 7 replicas (using kubectl scale deployment caching --replicas=7), all 7 Pods will be placed on the same Node as before.
I want to deploy some caching Pods on the web-cache-no-need Pods too because of a new requirement. How can I do that quickly?
Here is where we can use the power of complex string matching expressions inside the caching Pod manifest.

Once deployed, kube-scheduler will look up Pods with labels web-cache-affinity and web-cache-no-need and equally distribute caching Pods for both of them.
Pod Anti-Affinity
Since the options provided for Pod placement were a little thin (sarcasm alert), we were graced with another mechanism for Pod placement. This mechanism, Pod Anti-Affinity, is the evil (or good?) twin of Pod Affinity and just like its counterpart, uses labels and complex match expressions for Pod placements.
Demo: Pod Placement using Pod Anti-Affinity
So far, we've seen examples where Pod specs clearly mentioned WHERE they want to be deployed. With Anti-Affinity, the opposite is true (i.e. Pods tell kube-scheduler where they DON'T want to be deployed).
A visual of the Deployment manifest for this demo is below:

Step 1: Deploy the Pod for the manifest shown in Figure 14.

However, the real impact of the Anti-Affinity specifications will be obvious after we try to scale this Deployment from 1 to 4 replicas.
Step 2: Scale the Deployment 'web-server' from 1 replica to 4.
This can be done imperatively using 'kubectl scale deployment web-server --replicas=4'.
Step 3: Check which Nodes have the Pods placed on them.

Barring the Control Plane (which does not get a Pod deployed due to reasons like Taint/Tolerations), we expected kube-scheduler to distribute 4 Pods across the 3 Worker Nodes.
BUT we notice this is not the case. One of the four Pods is PENDING. Why?
- kube-scheduler will notice a request for placing 4 Pods on the cluster.
- kube-scheduler will pick up the manifest and go through the Pod specs.
- kube-scheduler will notice the manifest clearly tells it to place the web-server Pod on a Node which already does not have a web-server Pod on it. Refer to Figure 14 for visual confirmation.
- kube-scheduler will go to a Worker Node 1 and check if there is a Pod with app=web-server label on it. It won't find it and place the first replica there.
- kube-scheduler will then go to Worker Nodes 2 and 3, find there are no Pods there with app=web-server label on it and put one replica each on Worker Node 2 and 3.
- With one more replica left to place, kube-scheduler will realize that all 3 Worker Nodes have a Pod with the app=web-server label. Suddenly, we have a situation where a Pod is ready to be placed but our desire (expressed through the Pod spec) to keep one web-server Pod per Node, is presenting a hard constraint, which kube-scheduler cannot ignore.
- Therefore, we have a situation where the 4th replica is left PENDING.
However, we can tweak the Deployment manifest ever so lightly and ensure all 4 Pods get a house.
The reason kube-scheduler has to deal with this hard constraint of 'one web-server Pod per Node' is due to the requiredDuringSchedulingIgnoredDuringExecution rule. This is a mandatory rule and has to be followed. The kube-schedulers hands are tied.
If we were, however, to change the severity of this rule from MUST to PREFERABLY, kube-scheduler gets some wiggle room.
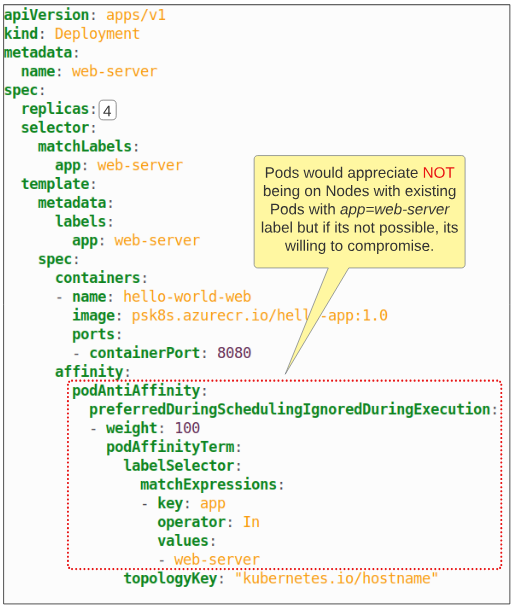
After updating our Deployment, when we check Pod placement across Pods, we notice all of them were scheduled.

The examples shown here are very basic in nature. In a real production environment, it is likely that a Pod spec will have a combination of Affinity and Anti-Affinity rules. Be aware though that the complexity introduced by using Affinity & Anti-Affinity (including the required and preferred checks) can become an operational hazard.
I write to remember and if in the process, I can help someone learn about Containers, Orchestration (Docker Compose, Kubernetes), GitOps, DevSecOps, VR/AR, Architecture, and Data Management, that is just icing on the cake.