K8s Deployment: Deploying and Maintaining Applications with Jobs.

Deployments, ReplicaSets and DaemonSets are all controllers that have the job of starting up a Pod and then ensuring that it (or a substitute) is always running and is always online. While long-running processes make up the large majority of workloads that run on a Kubernetes cluster, there is often a need to run short-lived, one-off tasks. The Job object is made for handling these types of tasks.
Table of Content
- What is a Job?
- Controlling Job Execution
- CronJobs
- Controlling CronJob Execution
- Demo: Jobs and CronJobs
- Demo: Failed Jobs and Restart Policy
- Demo: Parallel Jobs
- Demo: CronJobs
What is a Job?
Jobs create Pods that run until some termination condition is reached, after which the Pod is deleted. Regular Pods, controlled by Deployments, ReplicaSets and DaemonSets don't really ever END and continue to run.
Think of a situation where we need a Pod to help with database migration. Once the migration is done (termination condition is reached), the Pod has to be stopped or it will continue running in a loop, and repeat the tedious database migration over and over again.
Controlling Job Execution
K8s provides controls that we can use for controlling our Job execution.
- backoffLimit: The number of times a Job will retry, in case of failure, before it is considered FAILED. The dfault backoffLimit is 6.
- activeDeadlineSeconds: The maximum allowed run time for a Job. If the allowed run time is exceeded and the Job is not completed successfully, it is considered FAILED.
- parallelism: This is the maximum number of Pods running, due to a job, at the same time.
- completion: The desired number of Pods that are needed to finish successfully.
CronJobs
Sometimes you want to schedule a job to be run at a certain interval. Here is where CronJobs come into the picture. Much like their behavior in Linux and Unix systems, a CronJob will start at a scheduled time and uses the standard cron format.
Example of workloads where CronJobs are useful are backup of data at certain times, installation of software after a certain time of day etc.
Controlling CronJobs Execution
Built-in support for managing CronJobs is provided through:
- schedule: a cron formatted schedule that executes the job
- suspend: suspends the CronJob
- startingDeadlineSeconds: if the CronJob does not start within the time set as a value for this attribute, it is considered a FAILED job. However, the FAILED job will be executed again (or atleast will be queued for execution) when the next schedule becomes applicable.
- concurrencyPolicy: sometimes, it may happen, that a CronJob is executing and before this current execution ends, a new instance of the same CronJob is activated for parallel execution. K8s allows us to either Allow the job, Forbid it or Replace the current version with the newly activated instance.
Demo: Jobs and CronJobs
Step 1: Create the manifest.
The image below shows the manifest for our demo with some highlighted points
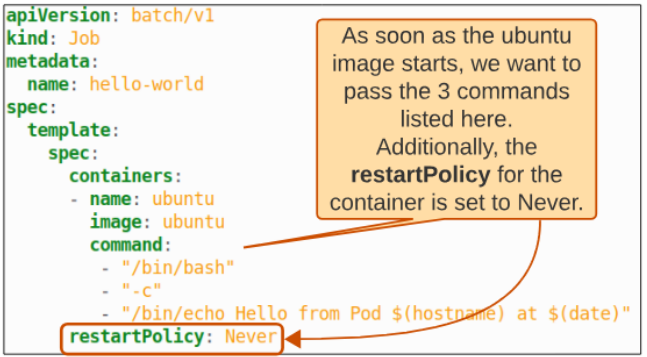
Using
kubectl create -f job.yaml
we can create and run the Job instantly.
Step 2: Investigate what happened during the Jobs execution.
We can start by looking at the Job object first using
kubectl get jobs

Using
kubectl describe job hello-world
will show us more details/metadata for hello-world Job
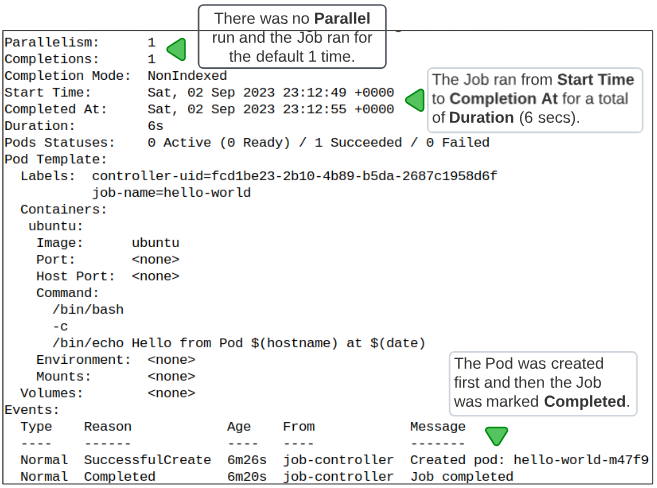
One of the line items in Figure 3 shows Pods Statuses: there are no active or failed Pods but there was one successful run.
To verify this claim being made by the Job metadata, we should list the Pods that were created as an outcome of this Job executing:

This is all fine and dandy but do we know if the commands we expected the Pod to execute were actually executed? To do that, we can look at the logs for the Pod.
Step 3: Look at Pod logs to confirm the specifications declared were successfully executed.
We can see the logs of our completed Pod using
kubectl logs <pod-name> or kubectl logs hello-world-m47f9

Demo: Failed Jobs and Restart Policy
Step 1: Create the manifest for a Job that will fail.

Step 2: Investigate Job Completion.
Once the Job has been created (using kubectl create -f failed-job.yaml), we can attach a watch switch to our Pods (kubectl get pods -w) to witness how a failed Job reacts to errors.
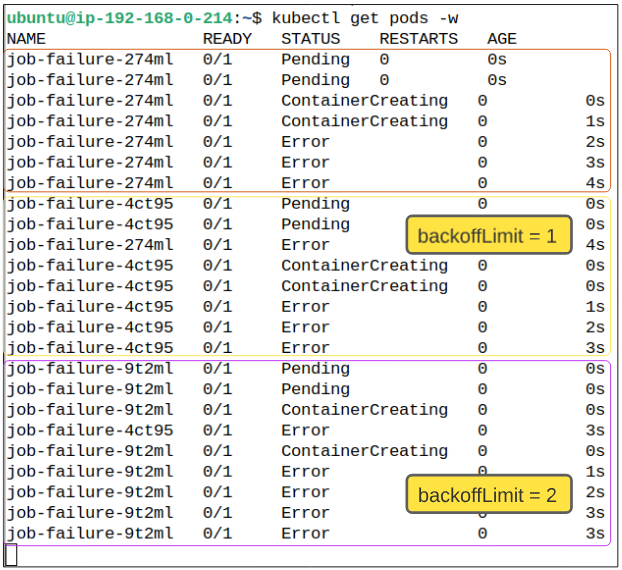
Notice the Job tried to spin up a Pod named job-failure-274ml, going from STATUS of Pending to Error. Since the backoffLimit was set to 2, the Job tried to complete the responsibility assigned to it twice more (which can be confirmed by noticing 2 more Pods, ending in 4ct95 and 9t2ml) and failing both times.
Since the restartPolicy is set to Never, a container failure means K8s will not try to work on fixing the containers problems (which would have happened if we set restartPolicy to OnFailure).
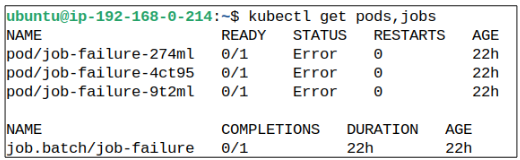
Additionally, the Job or the Pods created as part of the Jobs mandate are not deleted (as confirmed in Figure 8 below):
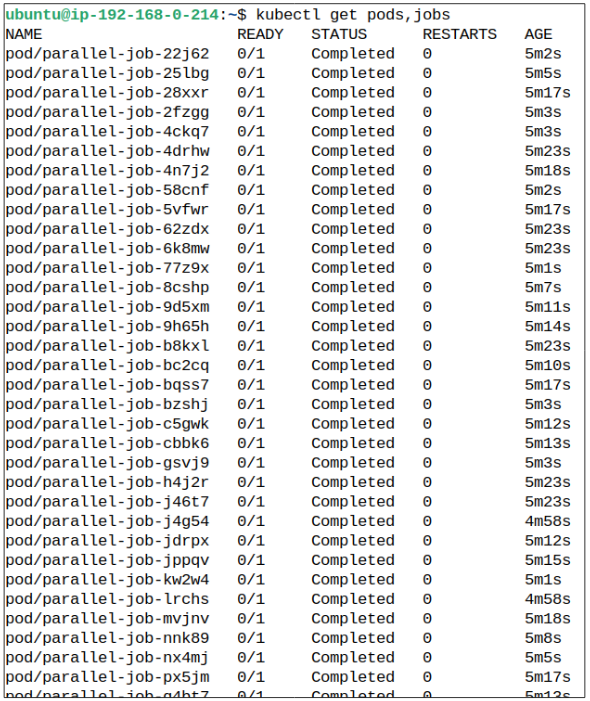
Demo: Parallel Jobs
Step 1: Create the Job manifest.

Step 2: Create the Job and investigate the outcomes.

Demo: CronJobs
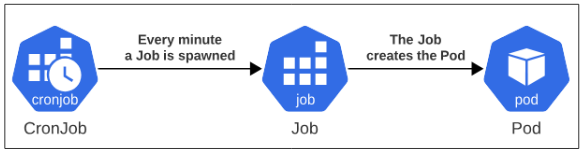
Finally, we will complete this article by looking at how a CronJob works. The core logic included in a CronJob is no different than that provided for a regular Job. The only difference is that CronJobs use cron format for scheduling the creation of a Job which then execute the core logic in the manifest.
Yup, thats right. The ONLY difference between a Job and a CronJob is the presence of a schedule inside the manifest. Based on the schedule, the CronJob object will create a Job object which then will fulfill the specs for the Pod(s).
Step 1: Examine the CronJob manifest.
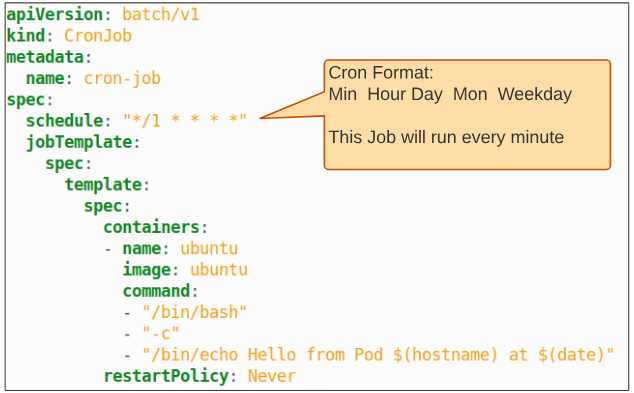
The cron format is depicted using a * for every temporal unit in a schedule. The schedule in the spec in Figure 12 has a 1 for the first '*' which is a placeholder for minutes.
Step 2: Execute the CronJob and investigate outcomes.
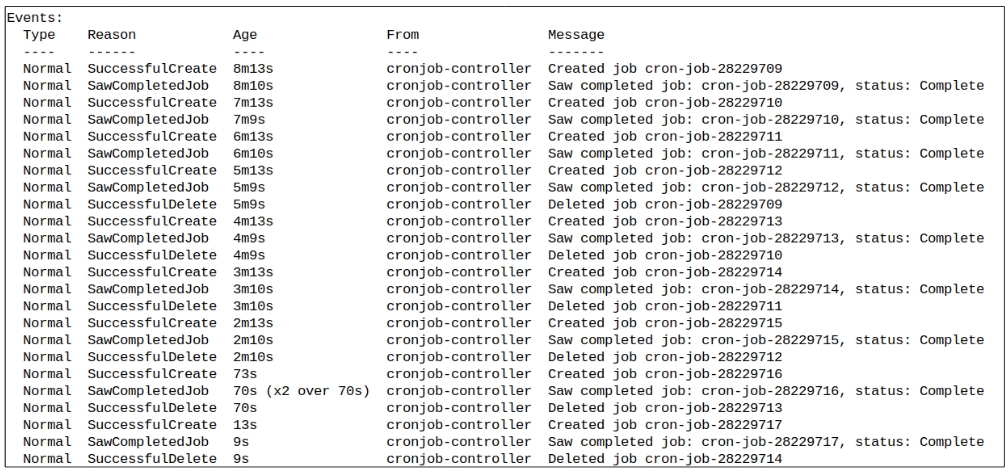
This is terrific BUT since we didn't specify the conditions under which this CronJob will stop its execution, and continue spinning up Pods and not deleting them, what about the storage and possible compute resources getting over allocated?
Aha ! Good question. If left to its devices, a CronJob as simple as the one we made for our demo can incur costs that we would rather avoid. Fortunately, the designers of K8s were also asking the same thing as us i.e. how can the cost and compute impact of CronJobs be mitigated?
It so happens that each CronJob has a default value of '3' for an attribute called successfulJobsHistoryLimit. This attribute tells Kube-API server how many Pods from successful runs should be kept around. The default value of '3' ensures that only the last 3 Pods from successful runs are allowed to be stored. All Pods prior to these 3 will be deleted.
I write to remember and if in the process, I can help someone learn about Containers, Orchestration (Docker Compose, Kubernetes), GitOps, DevSecOps, VR/AR, Architecture, and Data Management, that is just icing on the cake.