K8s Deployments: Maintaining and Managing Applications.

We can maintain application states with K8s Deployments and Deployment Controllers. If you want to get a basic understanding of Deployment Controllers, read this article.
Both of these requirements have to be upheld at all times and K8s, through its Deployments, Pods and Services ensures that, indeed, the committment made to end users is satisfied.
Deployments can configure and manage our applications. They can update the application, control rollout of new Pods and deletion of old Pods and also scale applications (up or down) depending upon our needs.
Table of Contents
- How does a Deployment object update our applications in a K8s cluster?
- How can we check the status of a new or edited Deployments?
- How can we control an applications rollout?
How does a Deployment object update our applications in a K8s cluster?
To understand the answer to this question, we need to look at the entire chain of events that are initiated the moment a Deployment object is sent to Kube-API server, ending at the point where an update to the Deployment (and consequently the Pods) is made.
Note: We assume a declarative approach for our demo.
Event 1: A manifest declaring a Deployment is created.
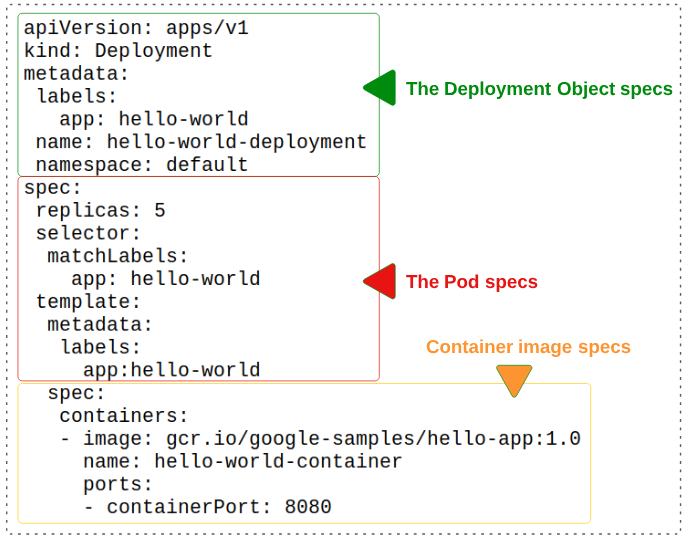
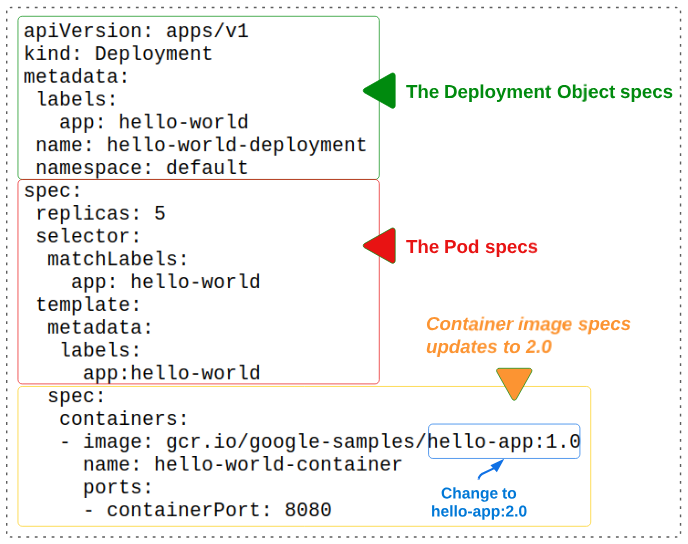
The Green section declares the metadata for the Deployment object that will be created:
- The Deployment object will be labelled "app: hello-world"
- It will be named "hello-world-deployment"
- It will be confined to the default namespace
The Red section is limited to Pod specs:
- We are asking for 5 Pods to be generated
- Every new Pod that is generated should have the label app: hello-world applied to it
The Orange section is all about the container image that will be hosted in the Pods:
- The container image is located at gcr.io/google-samples/hello-app:1.0
- The container will be named hello-world-container
- The container will be open at port 8080
Event 2: We use kubectl create -f <name of manifest>.yaml to create the Deployment object.
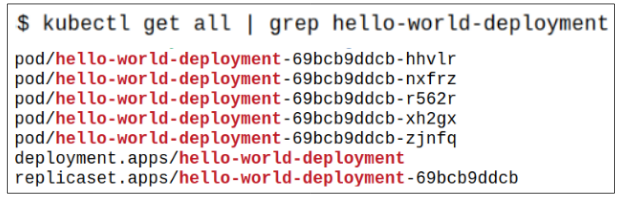
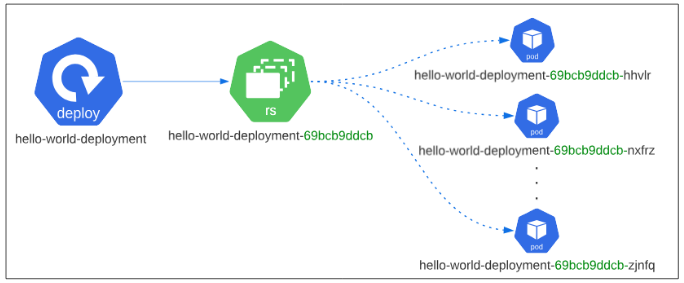
Visually, the relationship between Deployments, Replicaset and Pods would look as follows:
Event 3: A new version of the gcr.io/google-samples/hello-app is released, has a bug fix and we have to update the pod containers to this new version.
A new release of the hello-app code base has a critical bug fix and we have to make sure our Pods run the latest and greatest version of the container.
We will make one minor tweak in our deployment manifest:
Event 4: Apply the newly edited manifest to the cluster once again, using kubectl apply -f <name of manifest>.yaml.
Before applying this new manifest, check the existing Pods and their Replicaset.
After applying the new manifest (using kubectl apply -f deployment-manifest.yaml), check the new state of the Pods, Replicasets and Deployment.
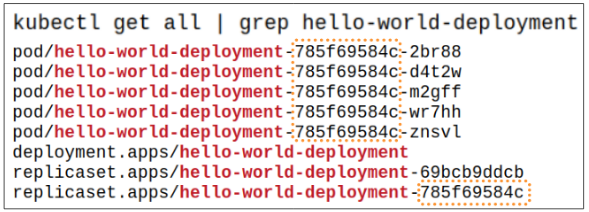
So what really happened?
- The Deployment Controller picked up the change in the manifest and passed it onto Kube-API server.
- The Deployment Controller created a new Replicaset (785f69584c).
- Pods that belonged to Replicaset 69bc9ddcb were killed and new Pods for Replicaset 785f69584c were generated. Each Pod being added to 785f69584c will be assigned a name which contains the new Pod template hash.
As per K8s architecture, Pods are registered as Endpoints with Services and therefore when old Pods are killed and replaced by new Pods, the Services will auto-update their Endpoint configuration to point to the new Pods, thus ensuring application availability.
For more details about Services and Pods, read this article.
Event 5: Kube-API will keep the old Replicaset in case we ever want to roll back our hello-app:2.0 to hello-app:1.0.
In Figure 7, both the old Replicaset (69bcb9ddcb) and new Replicaset (785f69584c) were shown. One would not be mistaken if they assumed that since the old Replicaset is no longer being used, it would be dropped by Kube-API. In fact, this does not happen. Kube-API will keep all versions of Replicasets attached to a Deployment. This is done to allow version rollbacking in case the need for that arises.
Though we used a declarative style in this example, we could have achieved the same results using imperative commands. Examples of such commands are provided below:
Using the set image command:
$ kubectl set image deployment <name of dep> <name of container>=image
$ kubectl set image deployment hello-world hello-world=hello-app:2.0
Using the set image with --record flag:
$ kubectl set image deployment <name of dep><name of container>=image
--record
--record captures additional metadata information and store it as an annotation in the Deployment. The additional metadata is very useful when we have to determine which previous version to rollback to.
Using kubectl edit deployment:
$ kubectl edit deployment <deployment-name>
$ kubectl edit deployment hello-world
The deployment being edited, will be opened in a text editor, allowing us to make the change and on saving it, there is a message sent back to Kube-API where its asked to help making the changes introduced.
How can we check the status of a new or edited Deployments?
We can use $ kubectl rollout status deployment <name of deployment> for this purpose.
Another kubectl command to use here is $ kubectl describe deployment <name of deployment>. The describe command provides a very detailed look inside the K8s object under investigation.
Complete: New Replicaset and associated Pods created successfully.
Progressing: New Replicaset and associated Pods are in the process of being created.
Failed: New Replicaset and associated Pods are erroring out. There are many reasons this may happen:
(1) container image is erroneous
(2) Namespace where Pods are being deployed is running out of Qouta and Resource Limits
(3) Replicaset or Deployment Controller have a defect etc.
Controlling Application Rollouts using Deployments
So far, we've seen, and demo'ed, how a Deployment object can update the core running containers that make up our applications. What we haven't spoken off is how we can use a Deployment object to also control the actual rollout.
There are 4 distinct ways in which rollouts can be managed:
- Through the use of an Update Strategy
- By pausing and then resuming an inflight rollout to make corrections
- By rolling back the containers to an earlier version
- By restarting a Deployment from scratch
Distinct Way # 1: Through the use of an Update Strategy
Currently, there are 2 Update Strategies that one can apply on a Deployment:
Update Strategy # 1: RollingUpdate (default)
- Is the default Update Strategy
- As a new Replicaset is scaling up and the required number of Pods are coming online, the old Replicaset and its Pods are scaled down. Both the scale-up and scale-down happen simultaneously which minimizes system downtime
- Allows us to set the number of Pods we are willing to have unavailable during the Deployment update through the maxUnavailable metric. The default value is 25% but it can be a fixed integer value or a percentage
- Uses maxSurge to ensure that only a certain number of Pod are created above the desired number of Pods per Replicaset. We may want to consider using maxSurge in situations where we have limit on resource usage and we have to be careful of them. The default is 25% but can be an integer or percentage value
Update Strategy # 2 Recreate:
- Before the new Replicaset and its Pods are scaled up, the existing Replicaset and its Pods are completely deleted.
Demo: Update Strategy w/ Health Probes
For this demo, we will use a manifest with Health Probes in the Pod specs.
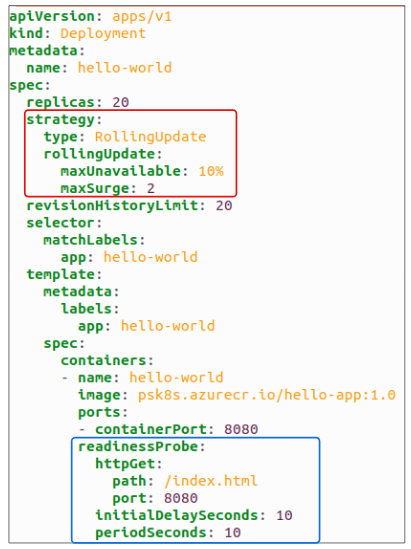
As per the strategy in the figure above, the RED block sets the following rule on number of Pods at any given moment in time:
- 18 Pods have to be working and accessible
- 22 Pods (functioning and broken as determined by the maxSurge value.
Additionally, the GREEN block tells us that a simple HTTP Get Probe will be checking the Pods health by sending a HTTP Request to an index.html page inside the container. This check will start 10 seconds after the Pod gets generated (*a good idea if Pods require bootstrapping) and once the first HTTP Request is sent, a subsequent Request will be sent every 10 seconds.
Distinct Way # 2: By rolling back the Deployment to an earlier version.
We have a new feature that works fine in Dev and QA and is now ready for prime time. The Release Manager has a Deployment manifest and s/he accidentally fat fingers the wrong value for a manifest attribute OR the container to use in the Pods has some undiscovered defect that kicks in, making the application unstable.
As we rollout the Deployment, we see these mistakes/errors become obvious. The simplest course of action would be to stop the rollout and revert to the previous working version while the problems are resolved.
Demo for rolling back to previous versions of a Deployment
Assume there is a version 1.0 of a certain software that is being released for the general public.
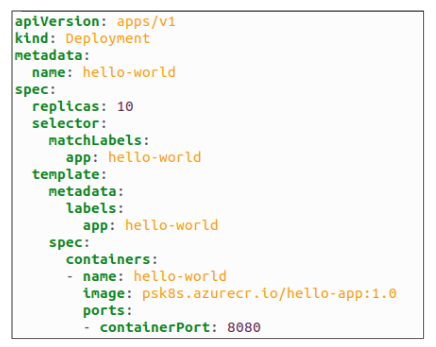
After we deploy the Pods, we can confirm 10 replicas where created and the system is in fully functional state.
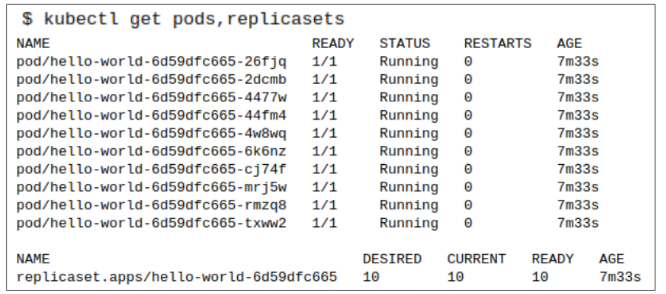
A few days pass, and we decide to roll out a new set of features for our app. We modify the Deployment manifest by updating the version of our app container to 2.0.
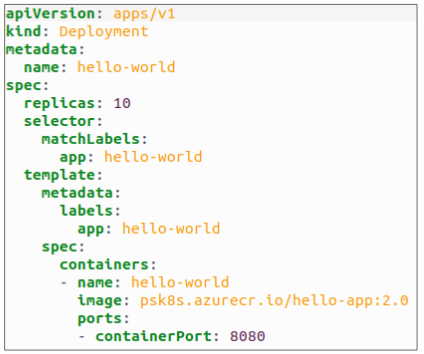

A few weeks later, a minor defect fix is made to v2 and this fix has to be pushed out. Of course, the process is the same as always: we execute kubectl apply -f <name of manifest file>.yaml and watch new Pods get generated and older Pods get deleted.
While making sure the manifest is correct, it is opened and an accidental typo is introduced in the manifest. The ypo is missed and the manifest is considered ready for prime time.
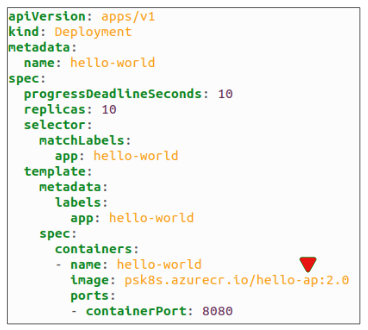
The new manifest is deployed, under the assumption there is no problem with its contents. We run the kubectl get pods command to see how the Deployment is progressing and notice something concerning.
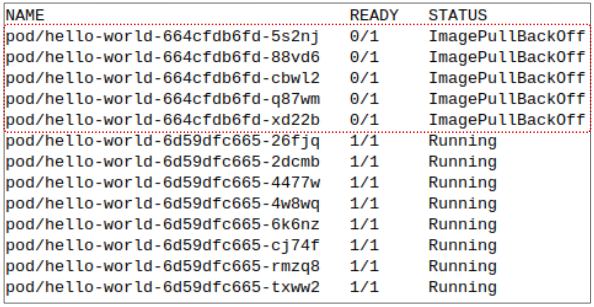
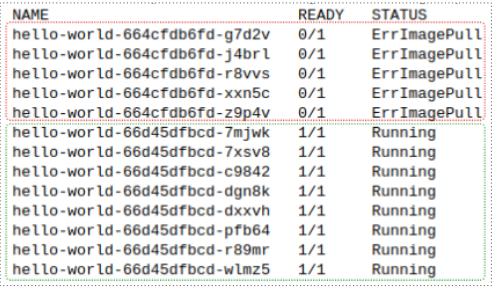
To understand whats going on, we need to look back at the first successful deployments manifest.
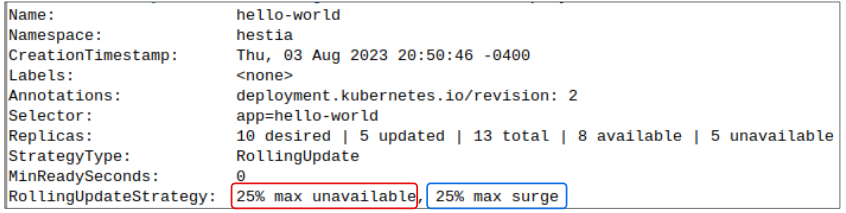
As per the RollingUpdateStrategy value,
- The hello-world Deployment can only have 25% Pods unavailable at any time. Since 25% of 10 is 2.5, K8s will round it down to 2 pods (you can't have half a Pod, obviously) and make SURE, there are at least 8 functioning Pods available at all times.
- The max surge is capped at 25% as well which means that in TOTAL (combining both the working and failing Pods) 12.5 Pods can exist at ANY one moment in time. K8s will round this up to 13, and stop generating additional Pods.
- Overall, 10 replicas are needed at any time, but this erroneous Deployment has resulted in 13 total Pods, of which 8 are working and 5 are not.
So now we are stuck in the situation where we have 8 Pods running a defective v2 of the app and the Pods with the fix are erroring out.
How do we get out of this problem?
- Option # 1: The RIGHT thing would be to fix the manifest and rerun the Deployment BUT in case this is not possible immediately,
- Option # 2: We could also rollback the failed deployment to its previous healthy state (i.e. v2 of the app that was released before the broken deployment).
We decide to follow option 2 for immediate relief.
We can run a check on the history of deployments to choose which one we should rever to, however, since we didn't use the --record flag, no CHANGE-CAUSE was recorded.

Alternatively, we can check the specific changes applied in each revision, which though tedious, is still useful.

Finally, we can rollback to the previous healthy revision (which in our case is revision 3).

I write to remember and if in the process, I can help someone learn about Containers, Orchestration (Docker Compose, Kubernetes), GitOps, DevSecOps, VR/AR, Architecture, and Data Management, that is just icing on the cake.