How do I and how often should data be loaded into an RDW?
[RDW = Relational Data Warehouse]
The answer to this question lies in the answer to two other questions:
- Question 1: How often is the data source refreshed with new data?
- Question 2: How frequently do users run analytics and/or generate reports?
If users don't need real-time data reporting or analysis and can wait for the next day to get information on the last 24 hours (or more), it is sensible to execute the ETL jobs during the night, after the data sources have been updated.
Another consideration is the size of the data that is being loaded. More data will result in a longer time for completion and if this delays the end users, perhaps there is an argument to be made for running more frequent loads over shorter periods.
Extraction Methods
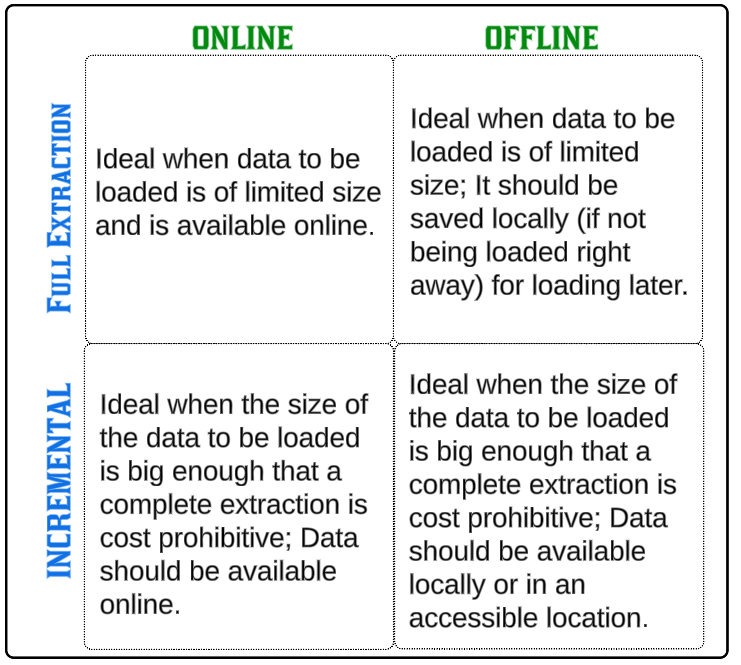
Full extraction
- All data from the source is loaded into the RDW.
- Usually, this is done if the source data is of a manageable quantity and loading it in one attempt does not go against any established SLA's for the end users.
Incremental extraction
- As the name suggests, only the data that has changed (edited or added new) is loaded to the RDW.
- This is usually done when the data sources are large and copying all data every time is operationally prohibitive. However, to ensure that only edited or newly added data is selected, we must use a counter like a timestamp or a sequence number for each record.
Online
- The data source to extract from is directly accessible from the RDW loading process.
Offline
- The data source is not always accessible (or not accessible when our ETL jobs are scheduled to run).
- Data is extracted from the data source when it is online or from intermediary storage that will hold the entire dataset (for small tables) or relevant new/edited data records
How do I know which data changed since the last extract was completed?
This is hard but still critical knowledge, especially if we incrementally load data into the RDW.
The tactics for determining which data records changed are listed below, from least to most preferred.
Using the MERGE statement
- Save data from the source into a temporary staging area (like a temp table).
- Compare the data in the temp table with that in the real table.
- The MERGE statement compares each column in the temp table with every column in the real table.
- Using this approach places a performance burden on the RDW's compute engine.
Using database triggers
- We can set up INSERT, UPDATE and DELETE triggers for each table in our data source(s).
- As soon as a record is updated, removed or added to the table, it is also recorded in a change tracking table.
- Our loading mechanism (for example an ETL job) can proceed to get changed data records from the change tracking table.
- Once the records have been loaded to the table in the RDW, the change tracking table should be emptied for the next round of trigger-driven changed data capture.
Using the built-in Changed Data Capture (CDC) feature
- Popular database engines like SQL Server have a built-in capability to perform CDC.
- The underlying tactics between a home-grown database trigger-driven CDC versus the built-in CDC capability may differ but the result is the same.
- Of course, using built-in CDC is far more optimal than using database triggers.
Using a date key to partition data
Add a date time column to a source data table and any record added/edited/deleted after a specific date/time is extracted and loaded. For example, if a Sales table had a date/time column, one could extract all records added in the last 24 hours.
Using Timestamps
Adding date/time columns with names like LAST_UPDATED is the most popular and relatively low-cost approach to finding changed data. As soon as a record is added/deleted/edited, the LAST_UPDATED column gets populated with a date and we can select records with a LAST_UPDATED column value within a specific range.
I write to remember, and if, in the process, I can help someone learn about Containers, Orchestration (Docker Compose, Kubernetes), GitOps, DevSecOps, VR/AR, Architecture, and Data Management, that is just icing on the cake.