Data Integration and Orchestration with Microsoft Fabric.
Types of Integration Architectures in Fabric
Batch Processing
Data is processed in large chunks and used when data freshness is not a primary concern.
Fabric supports batch processing through Dataflow Gen2 and Data Pipelines.
Real-Time Streaming
Data ingestion happens as soon as it arrives.
Fabric supports real-time streaming using Event Triggers, Dataflow Gen2 with incremental updates and Real-Time Hub.
Hybrid Integration
Data from on-prem and cloud-based sources is combined into one workflow.
Fabric supports hybrid integrations using Connectors, Data Gateways and Lakehouse.
On a tangent: Azure Data Factory vs Fabric Data Factory
Azure Data Factory and Fabric Data Factory both serve the same purpose: move data between source and destination. They both have:
- ELT/ETL Capabilities
- Many connectors
- Data Flows
- Pipelines
However, there are features unique to each one.
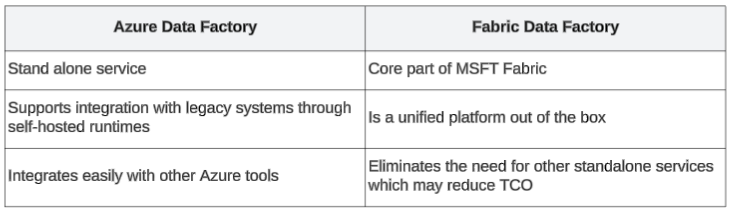
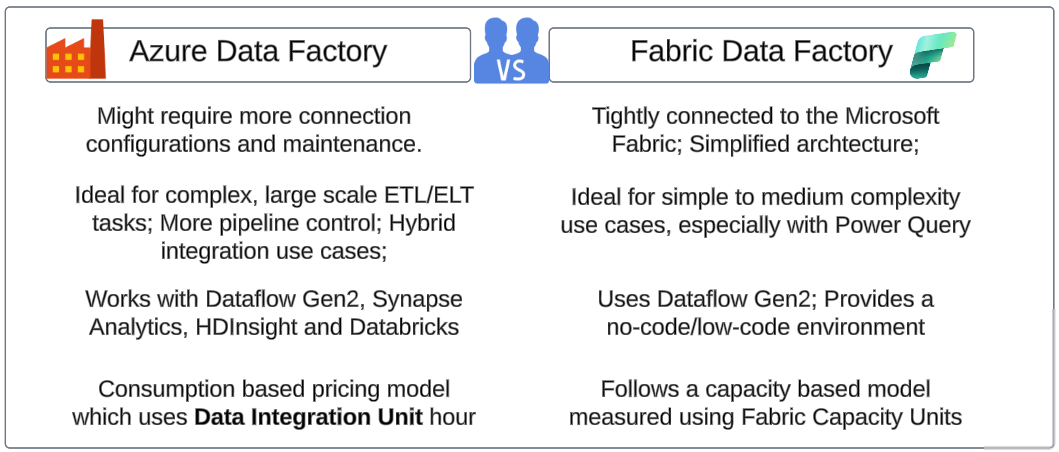
Which is the right tool for your needs?
The million-dollar question. With so many choices, which should we choose?
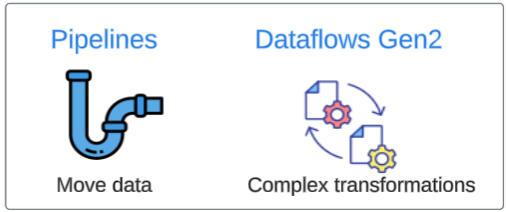
Difference between Integration and Orchestration
There is a difference between 'integration' and 'orchestration'.
Integration moves and transforms data from various sources to a destination(s).
Typically, Dataflow Gen2 and Data Pipelines are enough for integrations.
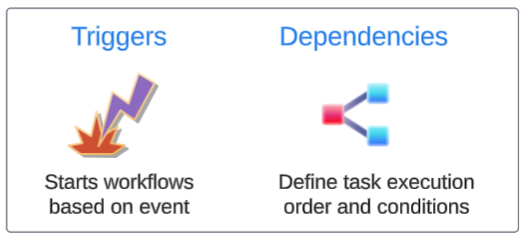
Orchestration, on the other hand, coordinates and automates multiple tasks, ensuring they execute in a prescribed sequence and under the right conditions.
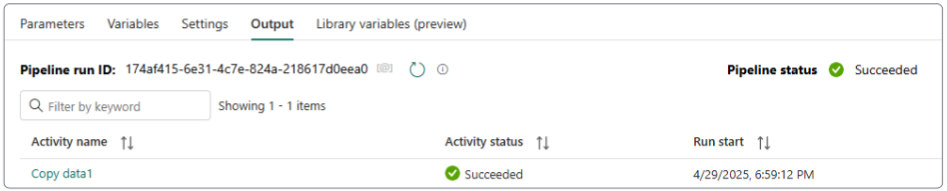
Demo: Loading data with Pipelines
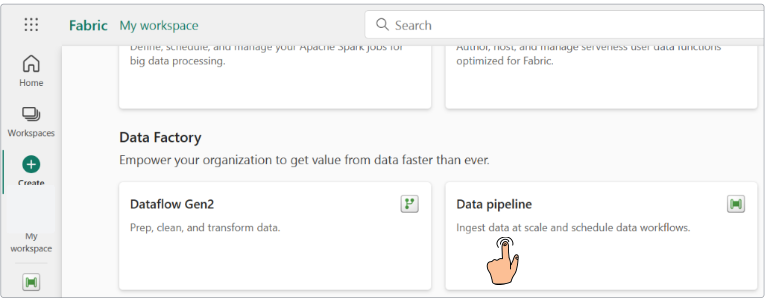
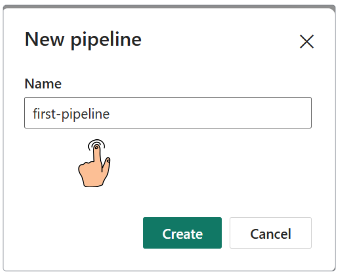
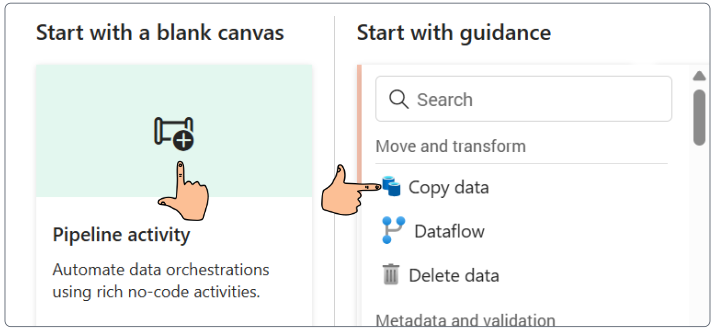
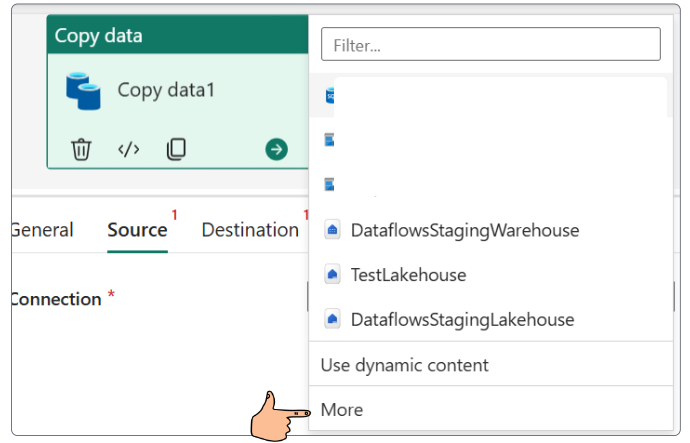
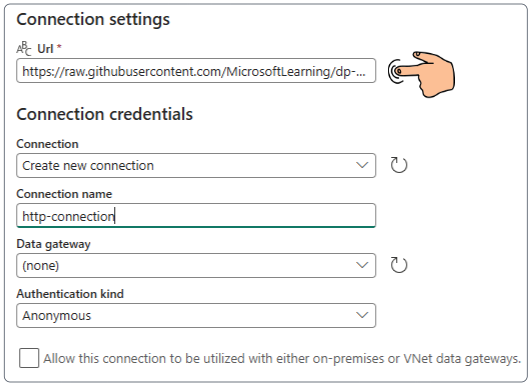
In this demo, we are connecting to an HTTP online source, therefore, there is no need to allow on-premise connections.
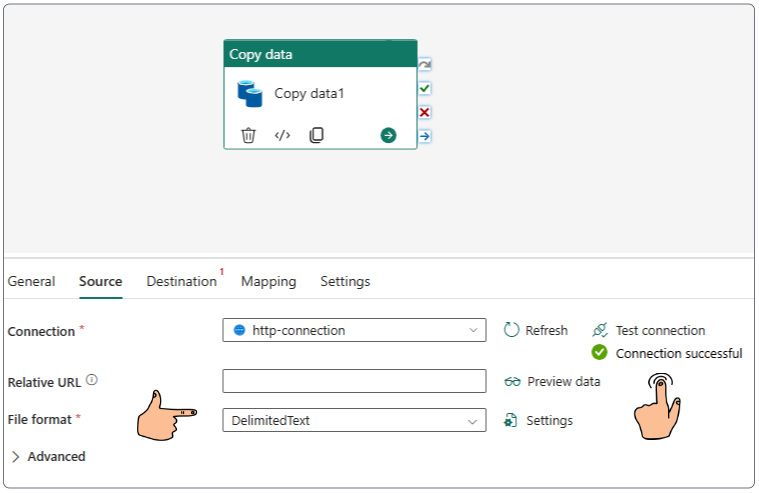
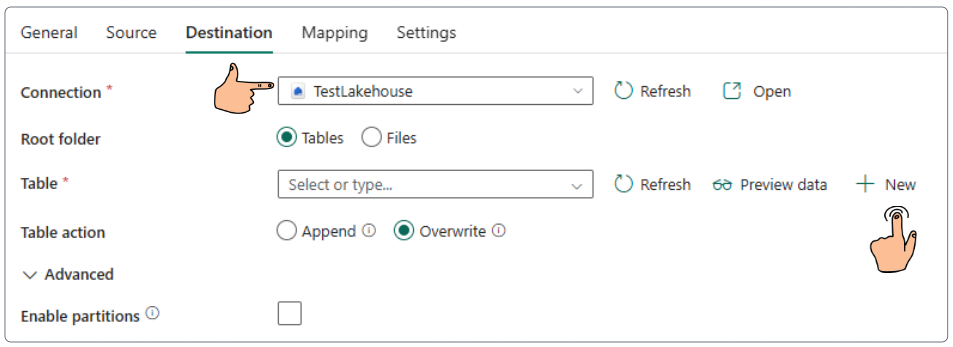
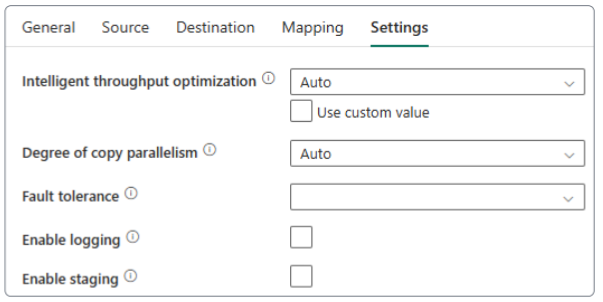
Demo: Loading data with DataFlows Gen2
Delete the order table that was created in the last demo.
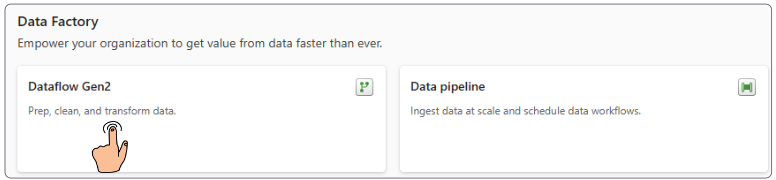
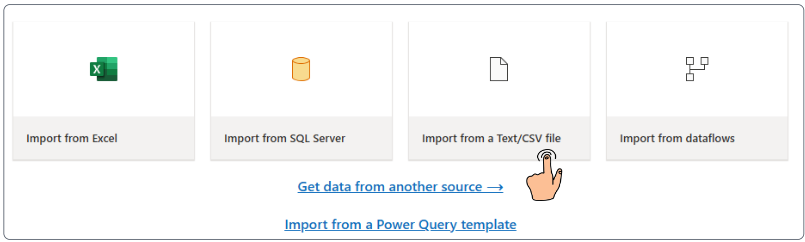
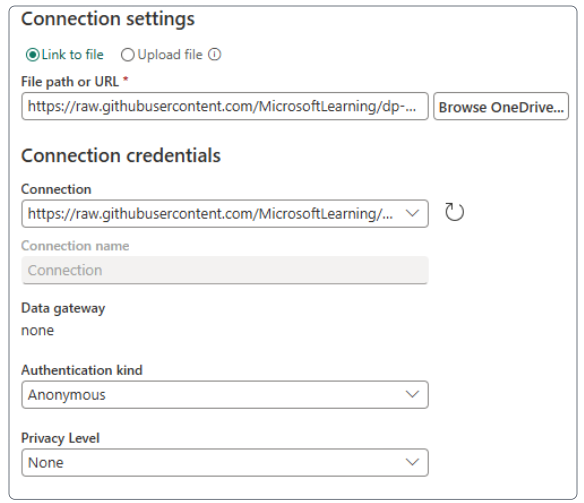
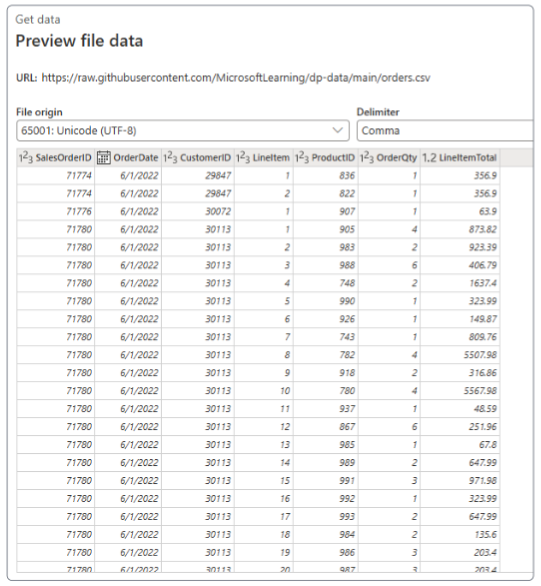
On successfully creating the Dataflow, the main console for Dataflow will appear.
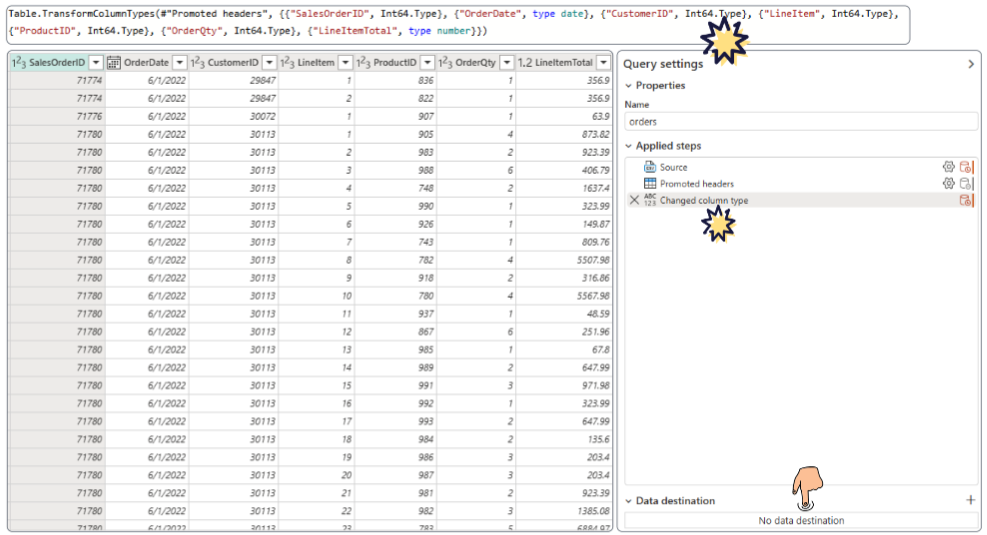
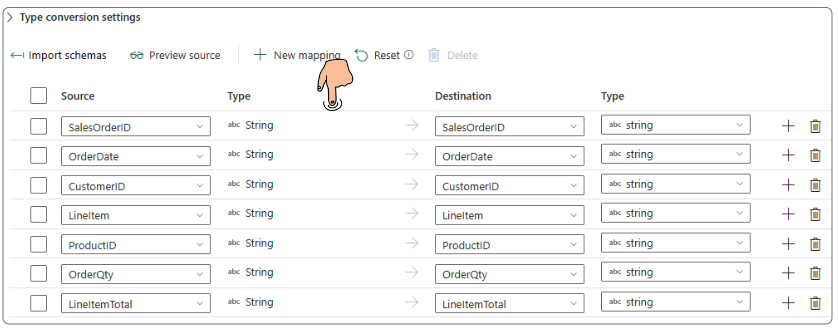
Dataflow changed column types as the data was being investigated. The Power Query syntax is provided as one step in the list of Applied steps.
Additionally, notice that no Data destination has been configured for this Dataflow yet.
Let's set a destination, then.
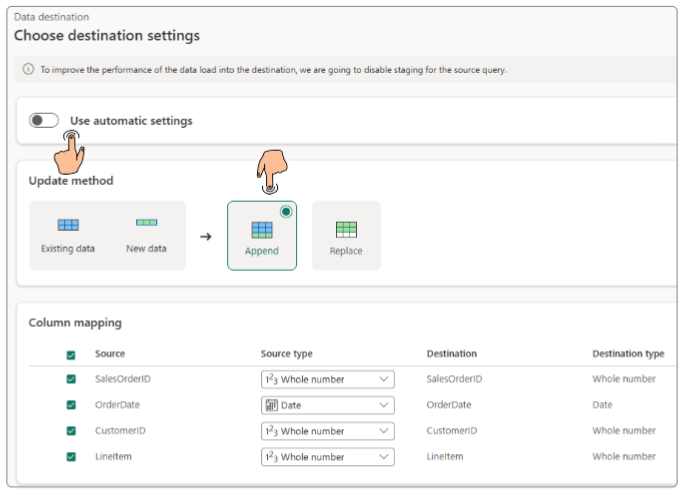
While Fabric Data Factory's "automatic settings" for data ingestion into a lakehouse can be convenient and efficient for many scenarios, there are several situations where relying solely on them can lead to undesirable outcomes or missed opportunities for optimization.
# 1: If the source system schema changes frequently.
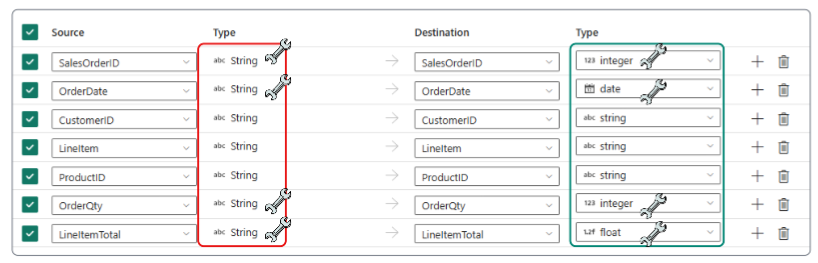
#2: When precise data types are crucial for downstream analysis. For example, financial data might require specific decimal precision.
#3: When optimal partitioning and distribution strategies for lakehouse tables must be configured manually.
#4: If raw data needs cleaning, transformation and enrichment.
#5: When source data contains complex structures that need to be transformed/flattened before saving.
At this point, the core component (dataflow) that will be used for data ingestion has been created. We will now wrap a pipeline around the Dataflow component to finish our demo.
The main pipeline authoring panel will appear (as indicated in the image below).
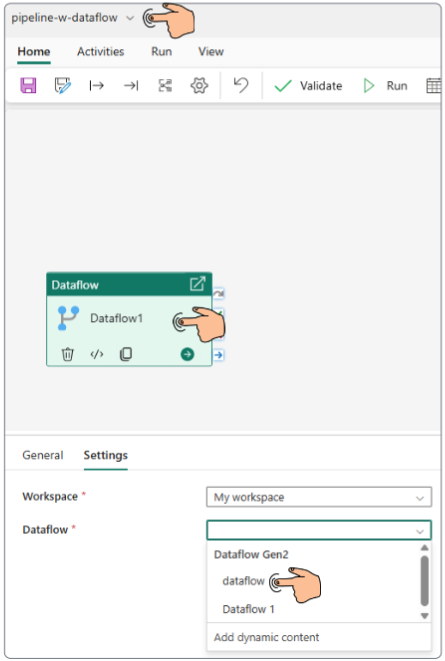
Validate and finally Run the pipeline.
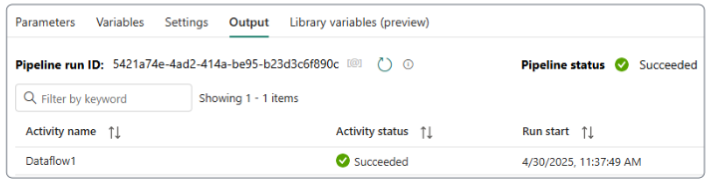
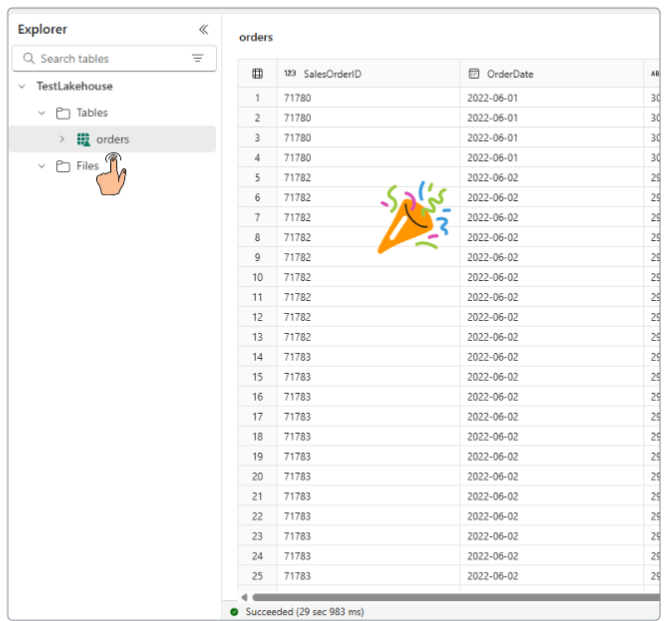
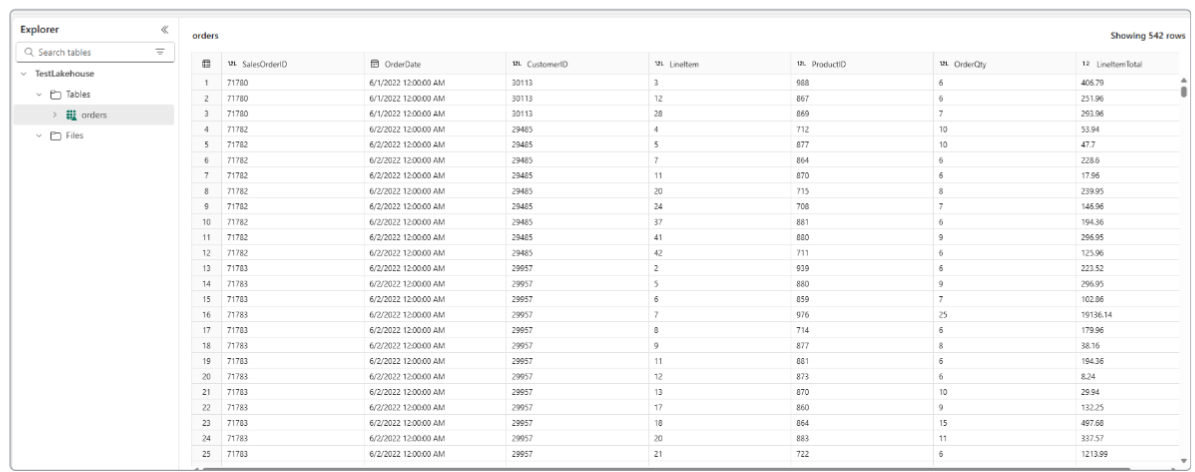
We can confirm dataflow worked as we had hoped by going to the lakehouse, and looking at the orders table (along with its data, of course).
What's the difference, then, between a Pipeline and a Dataflow?

I write to remember, and if, in the process, I can help someone learn about Containers, Orchestration (Docker Compose, Kubernetes), GitOps, DevSecOps, VR/AR, Architecture, and Data Management, that is just icing on the cake.