Commit Log: A Pattern for Data Durability.
Context: If a server acting like a data-store fails, we risk losing data which may not be recoverable. It is therefore important to use tactics that will provide guaranteed durability for our data stores even if the server that hosts it fail.
Webster defines du·ra·bil·i·ty as..
..the ability to withstand wear, pressure, or damage.
Example of wear, pressure, damage include, but may not be limited to, disk crashes, power outage leading to losing in-memory data, software malfunctioning or something as simple, yet dangerous, as executing the wrong command on a terminal.
How does Commit Log help with ensuring data durability?
Commit Log, also popularly called, Write-Ahead Log is a fairly popular approach used in most database systems.
Write-Ahead logging (aka WAL) involves data replication at the point data is being stored.
The visual below provides a high level process view for Write-Ahead logging.
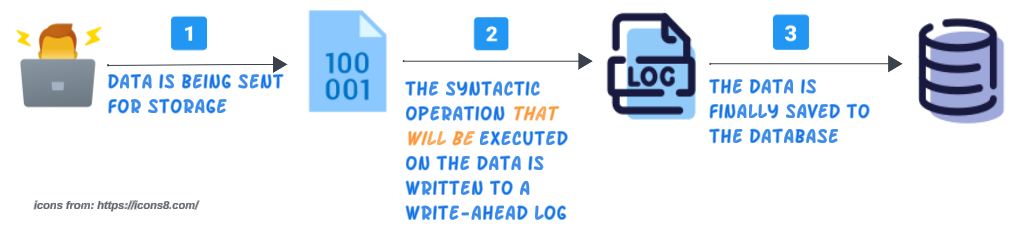
The log file, which has an append-only mode, will contain the list of all syntactic operations (such as CRUD statements). With each stream of data being sent for persistent storage, the log file will keep increasing in size and its contents, theoretically, could be considered a back up of our intent.
Use case for WA Log: Persistent Data Source Has Crashed.
John Smith is an ethnographer and collects a myriad of information, saves it in a database(s) for review and analysis in the future. He is on a 4 day data collection mission on a unique historical site and will be saving all data gathered during the first 3 days in a NoSQL database. On the 4th and last day of the project, the collected data will be synced with the main research database.
He collects a lot of interesting tit-bits, all of which he has saved in the database. On the morning of the 4th day, he gets asked to synchronize his main research database with all the information he's gathered. John, though not a techie, has some experience in data uploading and can trouble shoot basic issues. However, this time, he is going to face a situation he has never faced before - while uploading the data, the database server turned off due to a power surge.
He is petrified. In one stroke of bad luck, 3 days of effort has gone down the proverbial drain or has it?
Before leaving for his assignment, John had specifically asked for you because he knows you are a forward thinking engineer and have helped John overcome other technical challenges in the past.
He scurries over to you and bursts out crying.
"John, It's going to be ok. I had a suspicion the server allocated to you was not reliable so I preempted a solution in the event it did fizzle out". You then proceed to tell John what you did (through the use of the visual below).
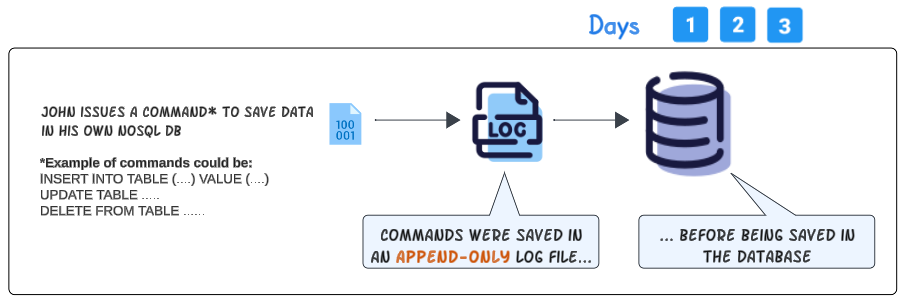
You were right to set up a separate file (the WA Log) and coded the stored procedures (for data entry) to do 2 things:
- Thing 1: Save the the issued command for the database as a new line entry in a WA Log, which is being saved in a local file folder.
- Thing 2: Once the entry in WA Log is successfully made, proceed to execute the issued command against the database.
As a result, at the end of work on Day 3, the state of information in the WA Log and the database will likely resemble the depiction below.
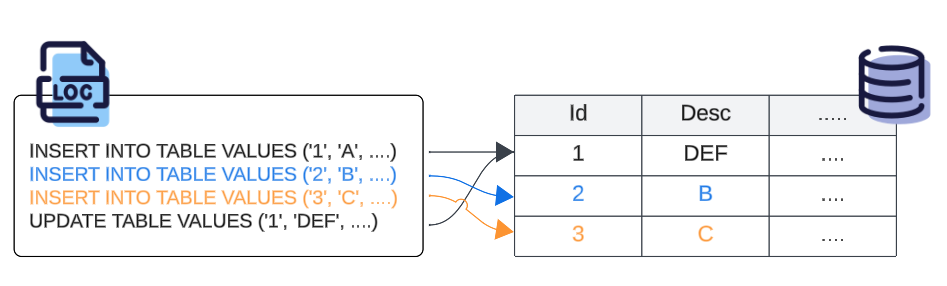
The WA Log contains the SQL commands issued (the intent) which resulted in the population of data columns in the database (the outcome).
On the morning of the 4th day (or the day John Smith's world stood still), after the database server broke down, you pulled up the WA Log from your local file folder. The WA Log contains all the SQL commands that were executed over the 3 days, along with the data values for each column.
After getting the server rebooted (and patched up a bit to make it less susceptible to faulting), you can run the commands inscribed in the WA Log (either through a Stored Procedure or some other means). Once John Smith's NoSQL database is ready and fixed, he can continue to syncing his discovered pieces of information with the main research database.
Implementation Wrinkles.
#1: Make sure the entries have been persisted to the WA Log.
Linux typically operates in write-back mode and flushes the buffer cache to disk approximately every 30 seconds. This means there is a lag of 30 seconds between the act of issuing instructions to append the SQL syntax to the end of the WA Log and the actual completion of it. If a power loss occurs inside these 30 seconds, appending to the WA Log could fail.
An OS agnostic remedy for this situation is to FORCE the files to be flushed to disk asap.
#2: Performance will likely suffer.
WA Log insertions process every data mutation operation and create a bottleneck for overall process performance.
Using techniques like batching to limit the impact on system performance.
#3: Duplicated entries in WA Log
In cases where retry logic on failure is used, we could end up with duplicated records. Unless of course there is logic coded to ensure duplicates are ignored, this could lead to incorrect analysis.
A collection object like HashMap can be used as the WA Log. Depending upon how the key-value pairs are semantically structured, updates to the same key result in an update of the value, as opposed to generating uniqueness errors from the WA Log.
I write to remember and if in the process, I can help someone learn about Containers, Orchestration (Docker Compose, Kubernetes), GitOps, DevSecOps, VR/AR, Architecture, and Data Management, that is just icing on the cake.